/** * A Handler allows you to send and process {@link Message} and Runnable * objects associated with a thread's {@link MessageQueue}. Each Handler * instance is associated with a single thread andthat thread's message * queue. When you create a new Handler, itis bound tothe thread / * message queue ofthe thread thatis creating it-- from that point on, * it will deliver messages and runnables tothat message queue and execute * them as they come out ofthe message queue. * * <p>There are two main uses for a Handler: (1) to schedule messages and * runnables to be executed assome point inthe future; and (2) to enqueue * an action to be performed on a different thread than your own. * * <p>Scheduling messages is accomplished withthe * {@link #post}, {@link #postAtTime(Runnable, long)}, * {@link #postDelayed}, {@link #sendEmptyMessage}, * {@link #sendMessage}, {@link #sendMessageAtTime}, and * {@link #sendMessageDelayed} methods. The <em>post</em> versions allow * you to enqueue Runnable objects to be called bythe message queue when * they are received; the <em>sendMessage</em> versions allow you to enqueue * a {@link Message} object containing a bundle of data that will be * processed bythe Handler's {@link #handleMessage} method (requiring that * you implement a subclass of Handler). * * <p>When posting or sending to a Handler, you can either * allow theitemto be processed as soon asthe message queue is ready * to do so, or specify a delaybeforeit gets processed or absolute timefor * itto be processed. The latter two allow you to implement timeouts, * ticks, and other timing-based behavior. * * <p>When a * process is created for your application, its main thread is dedicated to * running a message queue that takes care of managing the top-level * application objects (activities, broadcast receivers, etc) and any windows * they create. You can create your own threads, and communicate backwith * the main application thread through a Handler. This is done by calling * the same <em>post</em> or <em>sendMessage</em> methods asbefore, butfrom * your new thread. The given Runnable or Message will then be scheduled * inthe Handler's message queue and processed when appropriate. */
/** * Low-level class holding the list of messages to be dispatched by a * {@link Looper}. Messages are not added directly to a MessageQueue, * but rather through {@link Handler} objects associated with the Looper. * *<p>You can retrieve the MessageQueue for the current thread with * {@link Looper#myQueue() Looper.myQueue()}. */ public final class MessageQueue {
/** * Class used to run a message loop for a thread. Threads by default do * not have a message loop associated with them; to create one, call * {@link #prepare} in the thread that is to run the loop, and then * {@link #loop} to have it process messages until the loop is stopped. * *<p>Most interaction with a message loop is through the * {@link Handler} class. * *<p>This is a typical example of the implementation of a Looper thread, * using the separation of {@link #prepare} and {@link #loop} to create an * initial Handler to communicate with the Looper. * *<pre> * class LooperThread extends Thread { * public Handler mHandler; * * public void run() { * Looper.prepare(); * * mHandler = new Handler() { * public void handleMessage(Message msg) { * // process incoming messages here * } * }; * * Looper.loop(); * } * }</pre> */ public final class Looper {
/** * Run the message queue in this thread. Be sure to call * {@link #quit()} to end the loop. */ publicstaticvoidloop(){ final Looper me = myLooper(); if (me == null) { thrownew RuntimeException("No Looper; Looper.prepare() wasn't called on this thread."); } final MessageQueue queue = me.mQueue;
// Make sure the identity of this thread is that of the local process, // and keep track of what that identity token actually is. Binder.clearCallingIdentity(); finallong ident = Binder.clearCallingIdentity();
for (;;) { Message msg = queue.next(); // might block if (msg == null) { // No message indicates that the message queue is quitting. return; }
// This must be in a local variable, in case a UI event sets the logger final Printer logging = me.mLogging; if (logging != null) { logging.println(">>>>> Dispatching to " + msg.target + " " + msg.callback + ": " + msg.what); }
if (logging != null) { logging.println("<<<<< Finished to " + msg.target + " " + msg.callback); }
// Make sure that during the course of dispatching the // identity of the thread wasn't corrupted. finallong newIdent = Binder.clearCallingIdentity(); if (ident != newIdent) { Log.wtf(TAG, "Thread identity changed from 0x" + Long.toHexString(ident) + " to 0x" + Long.toHexString(newIdent) + " while dispatching to " + msg.target.getClass().getName() + " " + msg.callback + " what=" + msg.what); }
msg.recycleUnchecked(); } }
看到了这行吗? for (;;) Looper内的loop方法是一个死循环,这是为什么呢?想一想一个正常的线程应该是什么样的?从被创建到运行完run方法里面的代码,然后正常退出,那么我怎么样在线程中构建出UI界面这种永不结束的效果呢?为什么Android的UI可以在主线程中一直存在?很简单,因为主线程默认调用了Looper的loop方法,永不结束的从MessageQueue里取出Message处理,而我们刷新UI也就是向这个MessageQueue发送了一条Message。
The app namespace is not specific to a library, but it is used for all attributes defined in your app, whether by your code or by libraries you import, effectively making a single global namespace for custom attributes - i.e., attributes not defined by the android system. In this case, the appcompat-v7 library uses custom attributes mirroring the android: namespace ones to support prior versions of android (for example: android:showAsAction was only added in API11, but app:showAsAction (being provided as part of your application) works on all API levels your app does) - obviously using the android:showAsAction wouldn’t work on API levels where that attribute is not defined.
// loads the vertex shader and fragment shader, and links them to make the global gProgram staticvoidLoadShaders(){ std::vector<tdogl::Shader> shaders; shaders.push_back(tdogl::Shader::shaderFromFile(ResourcePath("vertex-shader.txt"), GL_VERTEX_SHADER)); shaders.push_back(tdogl::Shader::shaderFromFile(ResourcePath("fragment-shader.txt"), GL_FRAGMENT_SHADER)); gProgram = new tdogl::Program(shaders); }
// loads a triangle into the VAO global staticvoidLoadTriangle(){ // make and bind the VAO glGenVertexArrays(1, &gVAO); glBindVertexArray(gVAO); // make and bind the VBO glGenBuffers(1, &gVBO); glBindBuffer(GL_ARRAY_BUFFER, gVBO); // Put the three triangle verticies into the VBO GLfloat vertexData[] = { // X Y Z 0.0f, 0.8f, 0.0f, -0.8f,-0.8f, 0.0f, 0.8f,-0.8f, 0.0f, }; glBufferData(GL_ARRAY_BUFFER, sizeof(vertexData), vertexData, GL_STATIC_DRAW); // connect the xyz to the "vert" attribute of the vertex shader glEnableVertexAttribArray(gProgram->attrib("vert")); glVertexAttribPointer(gProgram->attrib("vert"), 3, GL_FLOAT, GL_FALSE, 0, NULL); // unbind the VBO and VAO glBindBuffer(GL_ARRAY_BUFFER, 0); glBindVertexArray(0); }
这里是真正绘制三角形的代码。 一点点看。 // make and bind the VBO
glGenBuffers(1, &gVBO);
glBindBuffer(GL_ARRAY_BUFFER, gVBO); // make and bind the VAO
glGenVertexArrays(1, &gVAO);
glBindVertexArray(gVAO); 这里创建一个VBO对象和VAO对象,并把它和OpenGL绑定 VBO和VAO是什么呢? VAO(Vertex Array Object)和VBO(Vertex Buffer Object)是C++程序和Shader程序传递数据使用的对象。 VBO存储要传递给Shader的数据,但是这里的数据没有类型。VAO对VBO和Shader进行连接,它描述了VBO存储的数据的类型,以及该传递个Shader的数据。
// Put the three triangle verticies into the VBO
GLfloat vertexData[] = {
// X Y Z
0.0f, 0.8f, 0.0f,
-0.8f,-0.8f, 0.0f,
0.8f,-0.8f, 0.0f,
};
glBufferData(GL_ARRAY_BUFFER, sizeof(vertexData),vertexData, GL_STATIC_DRAW); 这里向VBO添加数据,因为要绘制三角形,所以给VBO添加三个点的坐标值。 // connect the xyz to the "vert" attribute of the vertex shader
glEnableVertexAttribArray(gProgram->attrib("vert"));
glVertexAttribPointer(gProgram->attrib("vert"), 3, GL_FLOAT, GL_FALSE, 0, NULL); 调用VAO配置数据。这里设置变量的类型为vert。
// unbind the VBO and VAO
glBindBuffer(GL_ARRAY_BUFFER, 0);
glBindVertexArray(0); 最后对VBO和VAO解除绑定,因为以后不再需要它们了,这样也可以避免对数据误操作。
1 2 3 4 5 6 7 8
// run while the window is open while(!glfwWindowShouldClose(gWindow)){ // process pending events glfwPollEvents(); // draw one frame Render(); }
// draws a single frame staticvoidRender(){ // clear everything glClearColor(0, 0, 0, 1); // black glClear(GL_COLOR_BUFFER_BIT); // bind the program (the shaders) glUseProgram(gProgram->object()); // bind the VAO (the triangle) glBindVertexArray(gVAO); // draw the VAO glDrawArrays(GL_TRIANGLES, 0, 3); // unbind the VAO glBindVertexArray(0); // unbind the program glUseProgram(0); // swap the display buffers (displays what was just drawn) glfwSwapBuffers(gWindow); }
glClearColor(0, 0, 0, 1); // black
glClear(GL_COLOR_BUFFER_BIT); 清空屏幕,让窗口背景变成黑色。 `` // bind the program (the shaders) glUseProgram(gProgram->object());
// bind the VAO (the triangle)
glBindVertexArray(gVAO);
/** * A classfor managing and starting requests for Glide. Can use activity, fragment and connectivity * lifecycle events to intelligently stop, start, and restart requests. Retrieve either by * instantiating a newobject, ortotake advantage built in Activity and Fragment lifecycle * handling, use the static Glide.load methods with your Fragment or Activity. * * @see Glide#with(android.app.Activity) * @see Glide#with(android.support.v4.app.FragmentActivity) * @see Glide#with(android.app.Fragment) * @see Glide#with(android.support.v4.app.Fragment) * @see Glide#with(Context) */ publicclass RequestManager implements LifecycleListener
/** * A helper method equivalent to calling {@link #asDrawable()} and then {@link * RequestBuilder#load(Object)} with the given model. * * @return A new request builder for loading a {@link Drawable} using the given model. */ public RequestBuilder<Drawable> load(@NullableObject model) { return asDrawable().load(model); }
/** * Attempts to always load the resource using any registered {@link * com.bumptech.glide.load.ResourceDecoder}s that can decode any subclass of {@link Drawable}. * *<p> By default, may return either a {@link android.graphics.drawable.BitmapDrawable} or {@link * GifDrawable}, but if additional decoders are registered for other {@link Drawable} subclasses, * any of those subclasses may also be returned. </p> * *@return A new request builder for loading a {@link Drawable}. */ public RequestBuilder<Drawable> asDrawable() { return as(Drawable.class).transition(new DrawableTransitionOptions()); }
/** * Sets the specific model to load data for. * *<p> This method must be called at least once before * {@link #into(com.bumptech.glide.request.target.Target)} is called. </p> * *@param model The model to load data for, or null. *@return This request builder. */ @SuppressWarnings("unchecked") public RequestBuilder<TranscodeType> load(@Nullable Object model) { return loadGeneric(model); }
/** * Sets the {@link ImageView} the resource will be loaded into, cancels any existing loads into * the view, and frees any resources Glide may have previously loaded into the view so they may be * reused. * * @see RequestManager#clear(Target) * * @param view The view to cancel previous loads for and load the new resource into. * @return The * {@link com.bumptech.glide.request.target.Target} used to wrap the given {@link ImageView}. */ public Target<TranscodeType> into(ImageView view) { Util.assertMainThread(); Preconditions.checkNotNull(view);
if (!requestOptions.isTransformationSet() && requestOptions.isTransformationAllowed() && view.getScaleType() != null) { if (requestOptions.isLocked()) { requestOptions = requestOptions.clone(); } switch (view.getScaleType()) { case CENTER_CROP: requestOptions.optionalCenterCrop(context); break; case CENTER_INSIDE: requestOptions.optionalCenterInside(context); break; case FIT_CENTER: case FIT_START: case FIT_END: requestOptions.optionalFitCenter(context); break; //$CASES-OMITTED$ default: // Do nothing. } }
/** * Set the target the resource will be loaded into. * * @param target The target to load the resource into. * @return The given target. * @see RequestManager#clear(Target) */ public <Y extends Target<TranscodeType>> Y into(@NonNull Y target){ Util.assertMainThread(); Preconditions.checkNotNull(target); if (!isModelSet) { thrownew IllegalArgumentException("You must call #load() before calling #into()"); }
Request previous = target.getRequest();
if (previous != null) { requestManager.clear(target); }
private Request buildRequestRecursive(Target<TranscodeType> target, @Nullable ThumbnailRequestCoordinator parentCoordinator, TransitionOptions<?, ? super TranscodeType> transitionOptions, Priority priority, int overrideWidth, int overrideHeight) { if(thumbnailBuilder != null) { // Recursive case: contains a potentially recursive thumbnail request builder. if(isThumbnailBuilt) { throw new IllegalStateException("You cannot use a request as both the main request and a " + "thumbnail, consider using clone() on the request(s) passed to thumbnail()"); }
/** * A {@link Request} that loads a {@link com.bumptech.glide.load.engine.Resource} into a given * {@link Target}. * * @param <R> The type of the resource that will be transcoded from the loaded resource. */ publicfinalclassSingleRequest<R> implementsRequest,
@Override public void begin() { stateVerifier.throwIfRecycled(); startTime = LogTime.getLogTime(); if(model == null) { if(Util.isValidDimensions(overrideWidth, overrideHeight)) { width = overrideWidth; height = overrideHeight; } // Only log at more verbose log levels if the user has set a fallback drawable, because // fallback Drawables indicate the user expects null models occasionally. int logLevel = getFallbackDrawable() == null ? Log.WARN : Log.DEBUG; onLoadFailed(new GlideException("Received null model"), logLevel); return; }
/** * A factory responsible for producing the correct type of * {@link com.bumptech.glide.request.target.Target} for a given {@link android.view.View} subclass. */ publicclassImageViewTargetFactory{
/** * Sets the given {@link android.graphics.drawable.Drawable} on the view using {@link * android.widget.ImageView#setImageDrawable(android.graphics.drawable.Drawable)}. * *@param placeholder {@inheritDoc} */ @Override public void onLoadStarted(@Nullable Drawable placeholder) { super.onLoadStarted(placeholder); setResourceInternal(null); setDrawable(placeholder); }
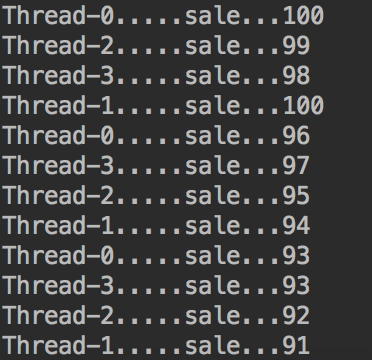
 输出的结果如图,我来一点点分析。
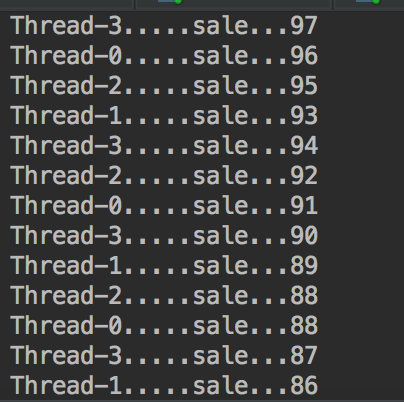
输出的结果如图,我来一点点分析。